- 运行环境:PC-windows操作系统
- 软件语言:简体中文|授权方式:
- 软件类型:国产软件 - 应用软件 - 编程相关
- 软件大小:143 KB
- 下载星级:
![]()
- 软件官网:暂无
- 更新时间:2015/8/6 12:02:00

本站提供的 html解析器(HtmlCleaner),html解析器(HtmlCleaner)编程工具下载 软件免费下载。
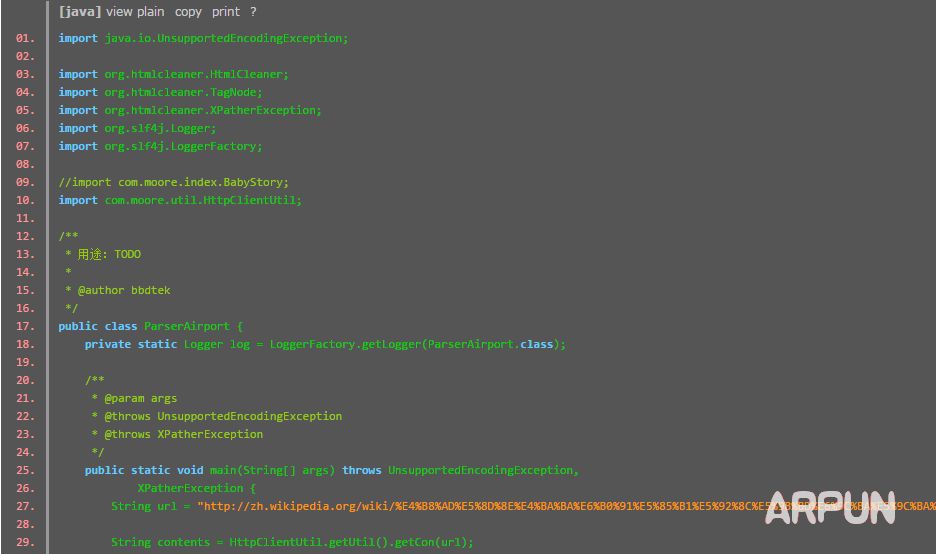
【软件截图】
【基本介绍】
HtmlCleaner是一个免费开源的适用范围广的java程序设计design语言语言Html文档解析器, 它能重新整理HTML文档的每个元素并生成结构良好(Well-Formed)的 HTML 文档。 默认它遵循的规则是类似于大部份web浏览器为创文档对象模型所使用的规则, 户可以能够提供自已来定义tag和规则组来来进行过滤和匹配。
HtmlCleaner软件特色
它被设计的小, 快速, 灵活而且独立。 HtmlCleaner也可用就在Java代码中, 当命令行必备工具或Ant任务。 解析后编程轻量级文档对象, 能够很容易的被转换到DOM或者JDom标准文档, 或者可以通过各种方式(压缩, 打印)连续输出XML。
HtmlCleaner使用示例
写一个测试用的html文件程序:html-clean-demo.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd " >
< html xmlns = "http://www.w3.org/1999/xhtml " xml:lang = "zh-CN" dir = "ltr" >
< head >
< meta http-equiv = "Content-Type" content = "text/html; charset=GBK" />
< meta http-equiv = "Content-Language" content = "zh-CN" />
< title > html clean demo </ title >
</ head >
< body >
< div class = "d_1" >
< ul >
< li > bar </ li >
< li > foo </ li >
< li > gzz </ li >
</ ul >
</ div >
< div >
< ul >
< li > < a name = "my_href" href = "1.html" > text-1 </ a > </ li >
< li > < a name = "my_href" href = "2.html" > text-2 </ a > </ li >
< li > < a name = "my_href" href = "3.html" > text-3 </ a > </ li >
< li > < a name = "my_href" href = "4.html" > text-4 </ a > </ li >
</ ul >
</ div >
</ body >
</ html >
Html代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="zh-CN" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK"/>
<meta http-equiv="Content-Language" content="zh-CN"/>
<title>html clean demo</title>
</head>
<body>
<div class="d_1"