- 运行环境:PC-windows操作系统
- 软件语言:简体中文|授权方式:最新版
- 软件类型:国产软件 - 图形图像 - 图像工具
- 软件大小:17.0 KB
- 下载星级:
![]()
- 软件官网:暂无
- 更新时间:2017/6/29 10:54:54

本站提供最新版的 python图片爬虫(图片爬虫工具) 软件免费下载。
【软件截图】
【基本介绍】
python图片PHOTO爬虫(图片爬虫必备工具)是一款特意为互联、it行业的小伙伴们打造的爬虫工具, 可以能够帮大家对软件来进行优化、seo的人一定会用的上哦, 有兴趣的赶紧下载了哦!python网络net爬虫抓取图片
相关推荐
图片爬虫 v1.1 当前最新版
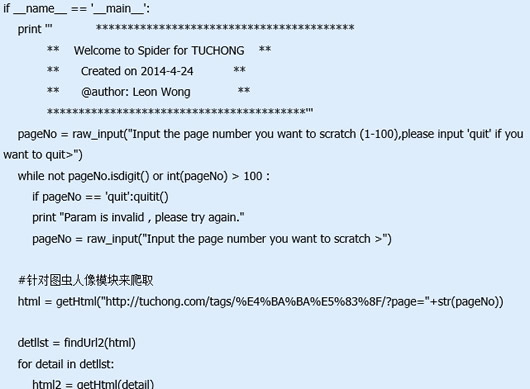
python图片爬虫代码如下:
#-*- encoding: utf-8 -*-
'''
Created on 2014-4-24
@author: Leon Wong
'''
import urllib2
import urllib
import re
import time
import os
import uuid
#获取二级页面url
def findUrl2(html):
re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?
url2list = re.findall(re1,html)
url2lstfltr = list(set(url2list))
url2lstfltr.sort(key=url2list.index)
#print url2lstfltr
return url2lstfltr
#获取html文本
def getHtml(url):
html = urllib2.urlopen(url).read().decode('utf-8')#解码为utf-8
return html
#下载图片到本地
def download(html_page , pageNo):
#定义文件程序夹的名字
x = time.localtime(time.time())
foldername = str(x.__getattribute__("tm_year"))+"-"+str(x.__getattribute__("tm_mon"))+"-"+str(x.__getattribute__("tm_mday"))
re2=r'http://photos.tuchong.com/.+/f/.+\.jpg'
imglist=re.findall(re2,html_page)
print imglist
download_img=None
for imgurl in imglist:
picpath = 'D:\\TuChong\\%s\\%s' % (foldername,str(pageNo))
filename = str(uuid.uuid1())
if not os.path.exists(picpath):
os.makedirs(picpath)
target = picpath+"\\%s.jpg" % filename
print "The photos location is:"+target
download_img = urllib.urlretrieve(imgurl, target)#将图片下载到指定路径中
time.sleep(1)
print(imgurl)
return download_img