
- 游戏介绍
- 相关版本
- 猜你喜欢
- 同类推荐
deepseek r1正式版是由深度求索(DeepSeek)公司推出的高性能 AI 助手,整体能力对标 OpenAI o1 正式版。该模型遵循 MIT License 开源协议,允许用户通过蒸馏技术基于 R1 训练自己的模型。deepseek r1现已开放 API 接口,并支持思维链输出功能,只需在调用时设置 model='deepseek-reasoner' 即可启用。模型在后训练阶段大规模采用强化学习技术,在几乎不依赖人工标注数据的前提下,显著提升了复杂推理能力,在数学、代码生成和自然语言推理等关键任务上表现卓越,整体性能与 OpenAI o1 正式版相当。
deepseek r1和v3的区别
DeepSeek-V3 和 DeepSeek-R1 是深度求索(DeepSeek)公司推出的两款人工智能模型。虽然二者共享部分技术基础(如混合专家架构 MoE),但在设计目标、训练策略、性能特点及适用场景等方面存在明显差异。以下是两者的核心区别:
1. 模型定位与核心能力
● DeepSeek-V3
定位为通用型大语言模型,重点覆盖自然语言处理、知识问答和内容生成等广泛任务。
采用混合专家架构(MoE),单次推理仅激活 370 亿参数(总参数达 6710 亿),大幅降低计算开销。
具备高效的多模态处理能力,可同时应对文本、图像、音频和视频等多种输入形式,且训练成本控制在 557.6 万美元,仅需 2000 块 H800 GPU。
在主流基准测试中表现接近 GPT-4o 和 Claude-3.5-Sonnet,更强调在多样化场景下的综合适应性。
● DeepSeek-R1
专为高难度推理任务打造,聚焦数学解题、代码生成和逻辑推演等专业领域。
在 DeepSeek-V3 架构基础上,引入大规模强化学习(RL)与冷启动技术,无需依赖大量监督微调(SFT)即可激发强大推理能力。
在 AIME 2024 数学竞赛和 Codeforces 编程挑战等高难度评测中表现突出,多项指标超越 OpenAI 的 o1 系列模型。
2. 训练方法与技术创新
● DeepSeek-V3
沿用经典的预训练加监督微调范式,结合 MoE 架构与负载均衡机制,实现高效计算资源利用。
引入多令牌预测(MTP)技术,在提升推理速度的同时增强任务完成质量。
● DeepSeek-R1
完全跳过监督微调阶段,直接通过强化学习从基础模型中挖掘并强化推理潜能。
核心技术包括 GRPO(群组相对策略优化)算法和两阶段强化学习流程,并配合冷启动数据优化初始模型状态。
模型在训练过程中自发形成反思机制与长链推理能力,展现出类人思维的高级行为特征。
3. 性能与基准测试对比
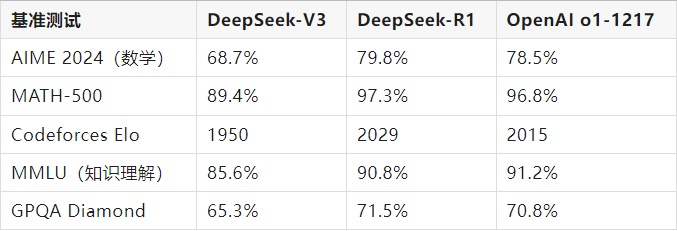
● DeepSeek-R1 在数学、编程及逻辑推理等需要深度思考的任务中表现更胜一筹,尤其适用于复杂问题求解场景。
● DeepSeek-V3 则在多语言理解与通用自然语言处理任务中表现更为均衡稳定。
4. 应用场景与部署成本
● DeepSeek-V3
适合对性价比要求较高的通用 AI 应用,如智能客服、内容创作(包括文案、小说等)以及知识问答系统。
API 定价亲民,输入价格为每百万 tokens 0.14 美元,输出为 0.28 美元,非常适合中小规模业务部署。
● DeepSeek-R1
面向科研探索、量化交易、专业代码生成等对推理精度要求极高的领域。
API 成本较高,输入为每百万 tokens 0.55 美元,输出达 2.19 美元,但支持模型蒸馏技术,可将强大推理能力迁移至小型模型(如 14B 参数版本),便于本地化或边缘端部署。
5. 开源生态与商业化
● DeepSeek-V3
作为开源模型,允许开发者自由修改与优化,已成功集成至 vLLM、LMDeploy 等主流推理框架。
● DeepSeek-R1
不仅开源模型权重(MIT 协议),还提供基于 Qwen 和 Llama 架构的蒸馏版本,参数规模覆盖 1.5B 至 70B,显著提升小模型在复杂任务中的表现。
总结
● DeepSeek-V3 凭借低成本与高通用性,适用于广泛的日常应用场景。
● DeepSeek-R1 则通过强化学习实现专业推理能力的突破,并依托灵活的蒸馏方案丰富了开源生态。
两款模型相辅相成,展现了 DeepSeek 在兼顾实用性和前沿技术探索上的战略布局。
deepseek api错误码一览
在调用 DeepSeek API 过程中,您可能会遇到各类错误提示。以下整理了常见错误码及其对应原因与解决方案,帮助您快速排查问题。

更新日志
v2.1.0版本
优化系统稳定性,修复若干已知问题。
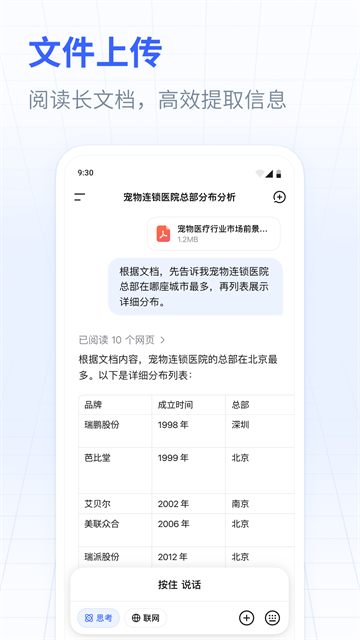
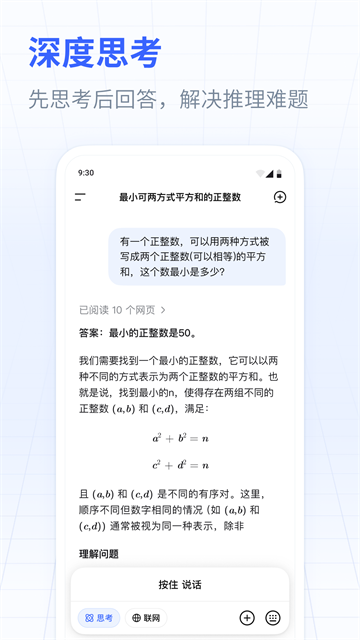
游戏截图



 面具Magisk中文模块仓库最新版v28.1
面具Magisk中文模块仓库最新版v28.1
 清浊高级版
清浊高级版
 sbti人格测试手机版
sbti人格测试手机版
 Firefox Focus隐私浏览器
Firefox Focus隐私浏览器
 光遇琴谱软件安卓版
光遇琴谱软件安卓版
 甲壳虫ADB助手最新版v1.4.0
甲壳虫ADB助手最新版v1.4.0
 铃声多多最新版免费v8.10.14.0
铃声多多最新版免费v8.10.14.0
 自动连点器免费版v2.0.12.28
自动连点器免费版v2.0.12.28
 八门神器游戏盒v4.0.2.1
八门神器游戏盒v4.0.2.1
 PUBGTool120帧画质助手v1.0.8.5
PUBGTool120帧画质助手v1.0.8.5
 画质修改助手手机版v1.1.1
画质修改助手手机版v1.1.1
 红果游戏盒子手机版v3.9.5.4
红果游戏盒子手机版v3.9.5.4
本类排行榜



最新更新
-
 七月棋牌老版本
七月棋牌老版本类型:休闲益智/大小:181MB
-
 天辰ios最新手机版
天辰ios最新手机版类型:卡牌策略/大小:75MB
-
 金丝猴jsh99
金丝猴jsh99类型:角色扮演/大小:77MB
-
 快乐炸金花金币版旧版本
快乐炸金花金币版旧版本类型:游戏辅助/大小:52MB
-
 领域斗地主连炸版
领域斗地主连炸版类型:模拟经营/大小:169MB
-
 芒果斗地主赢话费
芒果斗地主赢话费类型:卡牌对战/大小:710MB
-
 game728旧版本
game728旧版本类型:赛车竞速/大小:291MB
-
 山西大唐麻将
山西大唐麻将类型:模拟经营/大小:83MB
-
 捕鱼炸翻天至尊版
捕鱼炸翻天至尊版类型:战争策略/大小:704MB
-
 badam斗地主uygurqa维语版最新版
badam斗地主uygurqa维语版最新版类型:休闲益智/大小:78MB